
一、核心速览
(一)研究背景
- 研究问题:这篇文章要解决的问题是人员再识别(re-ID),即在网络摄像头图像集合中检索特定查询人物的照片。由于查询人物的外观和衣物属性在查询图像和集合图像之间保持不变,因此可以利用这些信息来提高检索性能。
- 研究难点:该问题的研究难点包括:目标的部分或完全遮挡、姿态变化、环境光变化、低图像分辨率等。
- 相关工作:现有的再识别方法主要分为两类:度量学习方法(如三元组和四元组损失)和分类方法。度量学习方法试图学习一个嵌入空间,使得同一人的图像靠近,不同人的图像远离。分类方法则基于
Softmax归一化和交叉熵损失进行训练。现有的方法通常利用语义信息如身体部位和人体姿态来提高分类和识别准确率,但尚未利用人员属性信息。
(二)研究方法
这篇论文提出了属性注意力网络 (AANet),用于解决人员再识别问题。具体来说,
全局特征网络
(GFN):该网络基于输入的查询图像进行全局身份(ID)分类。卷积特征图经过全局平均池化层后,通过1x1卷积层降维,再应用BatchNorm和ReLU激活函数,最后通过线性变换和Softmax函数进行分类。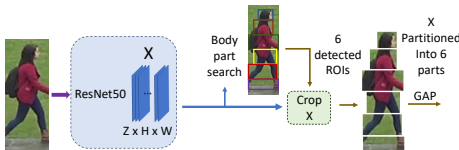
部分特征网络
(PFN):该网络专注于检测并提取局部化的身体部位。卷积特征图被分割成六个水平部分,通过识别每个特征图中的峰值激活区域来确定感兴趣区域(ROIs),并将这些区域聚类成六个bins,形成六个部分。然后对这些部分进行类似GFN的处理。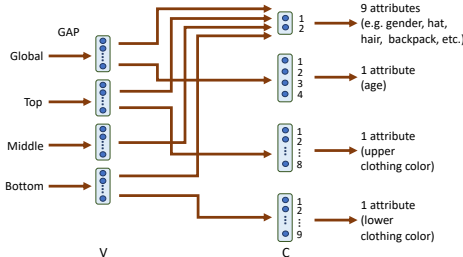
属性特征网络
(AFN):该网络利用人员属性进行特征提取和分类任务。AFN包含两个子任务:(i)属性分类;(ii)生成属性注意力图(AAM)。属性分类通过1x1卷积层将特征图的通道深度从Z降到V,然后将特征图分成三个不同的部分,分别提取不同属性的特征。AAM生成利用类敏感激活区域,通过最大操作合并各个属性的类敏感激活区域,并进行自适应阈值处理,以去除背景区域。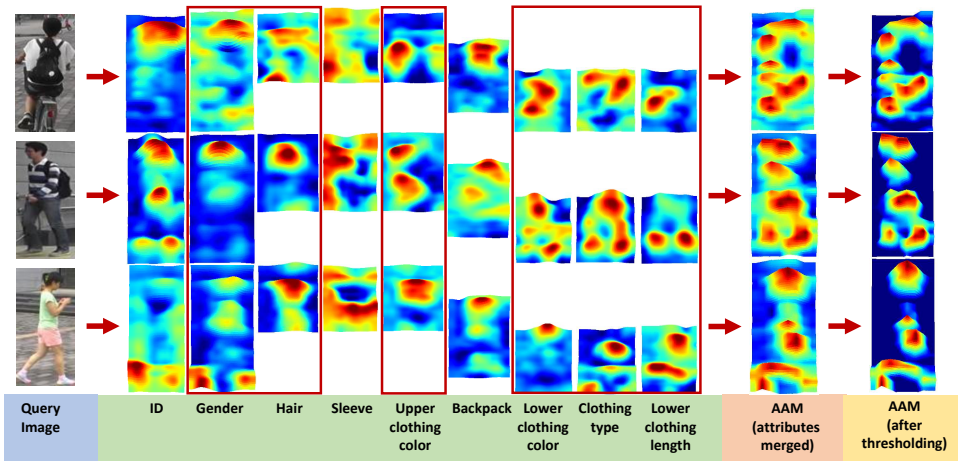
多任务损失计算:
AANet被构建为一个多任务网络,其多任务损失函数定义为: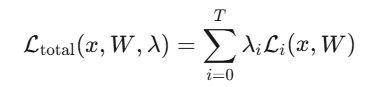
其中,x是训练图像集合,W是输入x的权重,T是任务损失总数,λ**i是任务损失加权因子。使用同质不确定性学习来优化任务损失的权重。
(三)实验设计
- 数据集:实验使用了
DukeMTMC-reID和Market1501两个数据集。DukeMTMC-reID数据集包含16,522张训练图像和17,661张gallery图像,共702个身份和408个干扰ID。Market1501数据集包含32,668张训练图像和15,913张测试图像,共751个身份。 - 图像预处理:训练图像被放大到384 x 128,数据增强方法仅为随机翻转。
ResNet-50的批量大小为32,ResNet-152的批量大小为24。 - 训练过程:使用随机梯度下降
(SGD)作为优化器,训练40个epoch。学习率对于新添加的层从0.1开始,对于预训练的ResNet参数从0.01开始,并在20个epoch时按阶梯计划减少0.1。
(四)结果与分析
DukeMTMC-reID数据集:AANet在ResNet-50上的mAP为72.56%,Rank-1准确率为86.42%;在ResNet-152上的mAP为74.29%,Rank-1准确率为87.65%。与现有的最先进方法相比,AANet在多个方面均表现出色。
Market1501数据集:AANet在ResNet-50上的mAP为82.45%,Rank-1准确率为93.89%;在ResNet-152上的mAP为83.41%,Rank-1准确率为93.93%。与现有的最先进方法相比,AANet同样表现出色。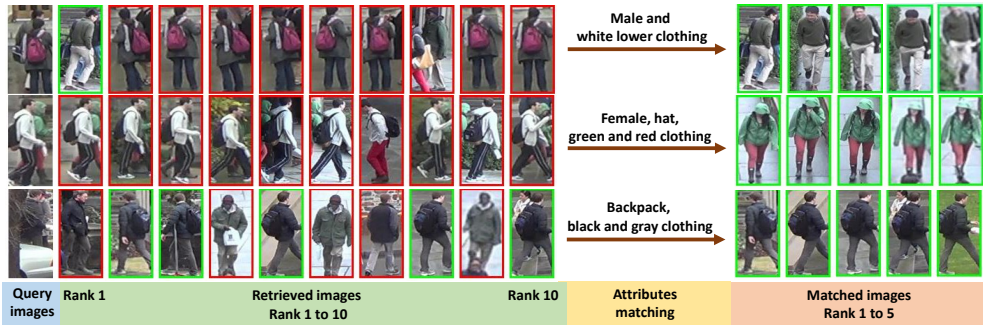
属性分类性能:
AANet在每个属性预测上的准确率均优于APR方法。
(五)总体结论
本文提出了一种新颖的架构,将基于物理外观的属性(如衣物颜色、头发、背包等)整合到基于分类的人员再识别框架中。通过联合端到端学习和同质不确定性学习进行多任务损失融合,AANet在多个基准数据集上均优于现有的最先进方法。
二、论文评价
(一)优点与创新
- 提出了一个新的网络架构,将属性特征与身份和身体部位分类集成在一个统一的学习框架中。
- 在多个基准数据集上超越了现有的最先进方法,提出了新的最先进解决方案。
- 利用同质不确定性学习来优化三个子任务的权重,从而提高最终损失计算的性能。
- 通过生成属性注意力图(
AAM),结合各个属性的类敏感激活区域,构建了更具辨别力的特征表示。 - 在
DukeMTMC-reID数据集上,AANet使用ResNet-50实现了 72.56% 的mAP和 86.42% 的 Rank-1 准确率,超越了现有的最先进方法。 - 在
Market1501数据集上,AANet使用ResNet-152实现了 83.41% 的mAP和 93.93% 的 Rank-1 准确率,再次超越了现有的最先进方法。 AANet还能够进行人物属性预测(如性别、头发长度、衣物长度等),并在查询图像中定位这些属性。
(二)不足与反思
- 论文中没有明确提到具体的不足和反思部分,但可以推测在数据增强和模型复杂度方面可能还有改进的空间。例如,虽然
AANet使用了较小的图像尺寸和较简单的训练过程,但在处理更复杂的遮挡情况时,可能需要进一步的研究和改进。
三、关键问题及回答
问题1:AANet中的属性注意力图 (AAM)是如何生成的?其作用是什么?
属性注意力图 (AAM)是通过属性分类任务生成的。具体步骤如下:
- 属性分类:首先,
AANet的属性特征网络(AFN)对每个人的各个属性进行分类。特征图被分成三个不同的部分,分别提取不同属性的特征。 - 类敏感激活区域:对于每个属性,使用类敏感激活区域(CAM)技术来定位图像中代表该属性的区域。CAM通过全局平均池化生成,能够揭示图像中与特定属性相关的区域。
- 合并激活区域:将各个属性的类敏感激活区域通过最大操作合并,形成一个特征图。
- 自适应阈值处理:对合并后的特征图进行自适应阈值处理,去除背景区域,最终生成属性注意力图
(AAM)。
AAM的作用是在身份分类过程中提供更具辨别力的特征。通过结合各个属性的类敏感激活区域,AAM能够更精确地定位到与查询图像相关的区域,从而提高身份分类的准确性。
问题2:AANet在实验中是如何验证其性能的?使用了哪些数据集和评价指标?
AANet在两个主要数据集上进行了验证:DukeMTMC-reID和 Market1501。具体的实验设计和评价指标如下:
- 数据集:
DukeMTMC-reID:包含16,522张训练图像和17,661张gallery图像,共702个身份和408个干扰ID。Market1501:包含32,668张训练图像和15,913张测试图像,共751个身份。
- 评价指标:
mAP(Mean Average Precision):衡量检索结果的平均精度,考虑了检索结果的排序。- Rank-1准确率:衡量查询图像与检索结果中第一个匹配项的准确率。
通过在这些数据集上的实验,AANet展示了其在人员再识别任务中的优越性能。例如,在 DukeMTMC-reID数据集上,AANet在 ResNet-50上的 mAP为72.56%,Rank-1准确率为86.42%;在 ResNet-152上的 mAP为74.29%,Rank-1准确率为87.65%。在 Market1501数据集上,AANet在 ResNet-50上的 mAP为82.45%,Rank-1准确率为93.89%;在 ResNet-152上的 mAP为83.41%,Rank-1准确率为93.93%。
问题3:AANet在处理遮挡和姿态变化的挑战时表现如何?
AANet通过以下机制有效应对遮挡和姿态变化的挑战:
- 属性信息利用:
AANet利用人员的属性信息(如性别、头发长度、衣物长度等)来辅助身份分类。这些属性信息在查询图像和集合图像之间通常保持不变,因此可以提供稳定的特征用于匹配。 - 局部化特征提取:通过部分特征网络
(PFN),AANet能够检测并提取局部化的身体部位。这种方法可以减少背景干扰,提高在遮挡情况下的识别准确性。 - 属性注意力图
(AAM):AAM结合了各个属性的类敏感激活区域,能够更精确地定位到与查询图像相关的区域。即使在姿态变化的情况下,AAM也能有效地捕捉到人物的显著特征。
实验结果表明,AANet在处理遮挡和姿态变化的挑战时表现出色。例如,在 Market1501数据集上,AANet的Rank-1准确率高达93.93%,显示出其在实际应用中的鲁棒性。
